
SD-v1.5

Modern diffusion models, particularly those utilizing a Transformer-based UNet for denoising, rely heavily on self-attention operations to manage complex spatial relationships, thus achieving impressive generation performance. However, this existing paradigm faces significant challenges in generating high-resolution visual content due to its quadratic time and memory complexity with respect to the number of spatial tokens. To address this limitation, we aim at a novel linear attention mechanism as an alternative in this paper. Specifically, we begin our exploration from recently introduced models with linear complexity, e.g., Mamba, Mamba2, and Gated Linear Attention, and identify two key features—attention normalization and non-causal inference—that enhance high-resolution visual generation performance. Building on these insights, we introduce a generalized linear attention paradigm, which serves as a low-rank approximation of a wide spectrum of popular linear token mixers. To save the training cost and better leverage pre-trained models, we initialize our models and distill the knowledge from pre-trained StableDiffusion (SD). We find that the distilled model, termed LinFusion, achieves performance on par with or superior to the original SD after only modest training, while significantly reducing time and memory complexity. Extensive experiments on SD-v1.5, SD-v2.1, and SD-XL demonstrate that LinFusion delivers satisfactory zero-shot cross-resolution generation performance, generating high-resolution images like 16K resolution. Moreover, it is highly compatible with pre-trained SD components, such as ControlNet and IP-Adapter, requiring no adaptation efforts.
We replace original self-attention layers in Stable Diffusion with the proposed LinFusion modules containing generalized linear attention. As shown in the left figure, knowledge distillation is applied to match their outputs with original self-attention layers. Only these modules are trainable, while other parameters are frozen.
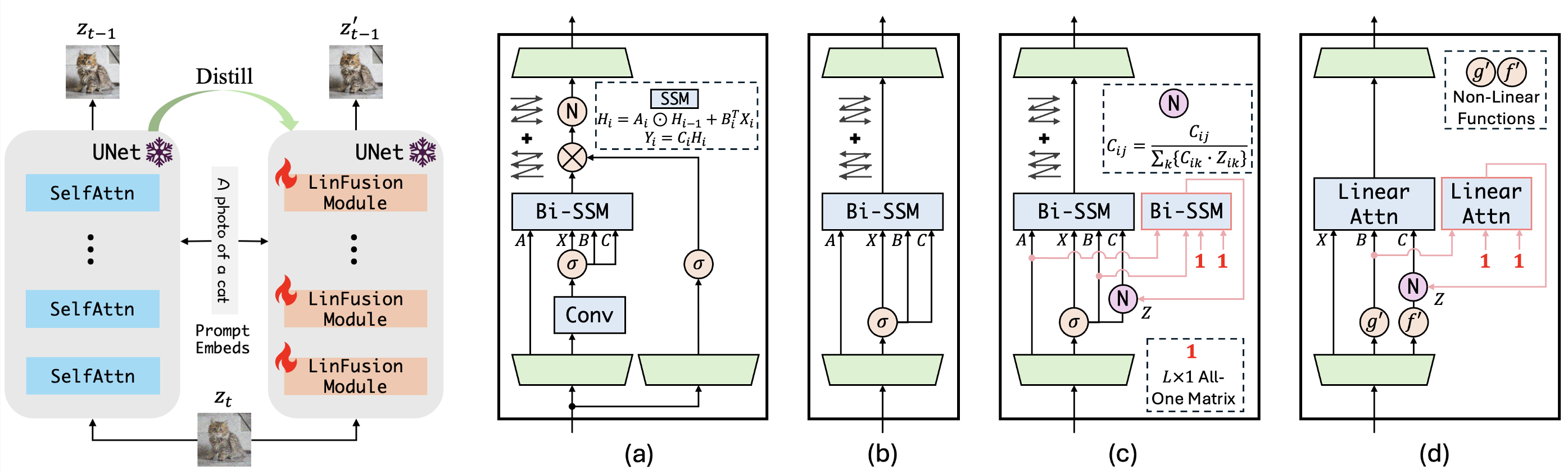
The proposed generalized linear attention can be viewed as a normalization-aware and non-causal version of Mamba2. For the right figure: (a) The architecture of Mamba2. Bi-directional SSM is additionally involved here. (b) Mamba2 without gating and RMS-Norm. (c) Normalization-aware Mamba2. (d) The proposed LinFusion module with generalized linear attention.
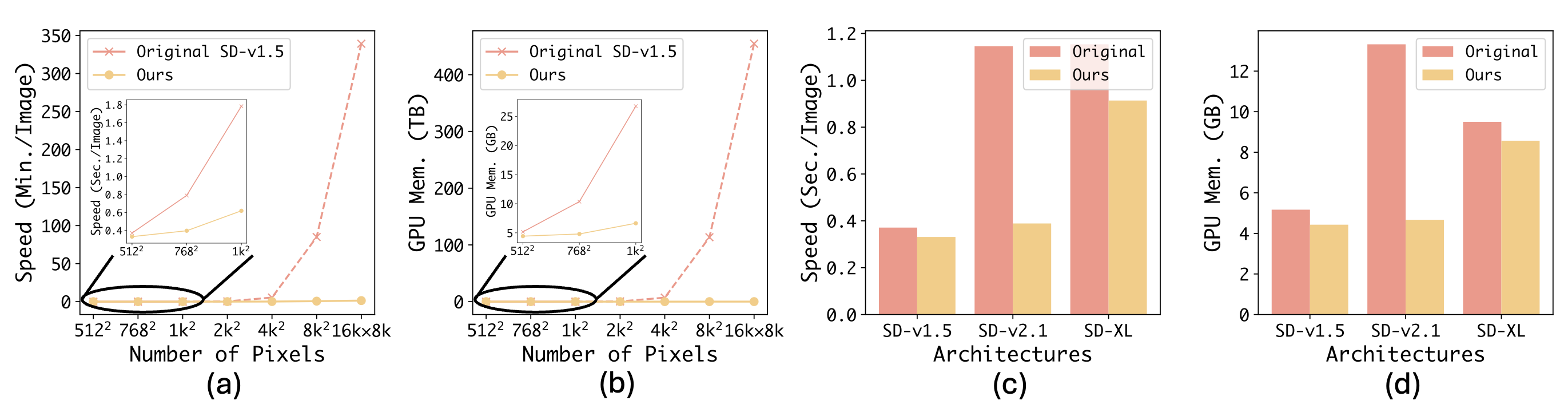
(a) and (b): Comparisons of the proposed LinFusion with original SD-v1.5 under various resolutions in terms of generation speed using 8 steps and GPU memory consumption. The dashed lines denote estimated values using quadratic functions due to out-of-memory error. (c) and (d): Efficiency comparisons on various architectures under their default resolutions.









@article{liu2024linfusion,
title = {LinFusion: 1 GPU, 1 Minute, 16K Image},
author = {Liu, Songhua and Yu, Weihao and Tan, Zhenxiong and Wang, Xinchao},
year = {2024},
eprint = {2409.02097},
archivePrefix={arXiv},
primaryClass={cs.CV}
}